
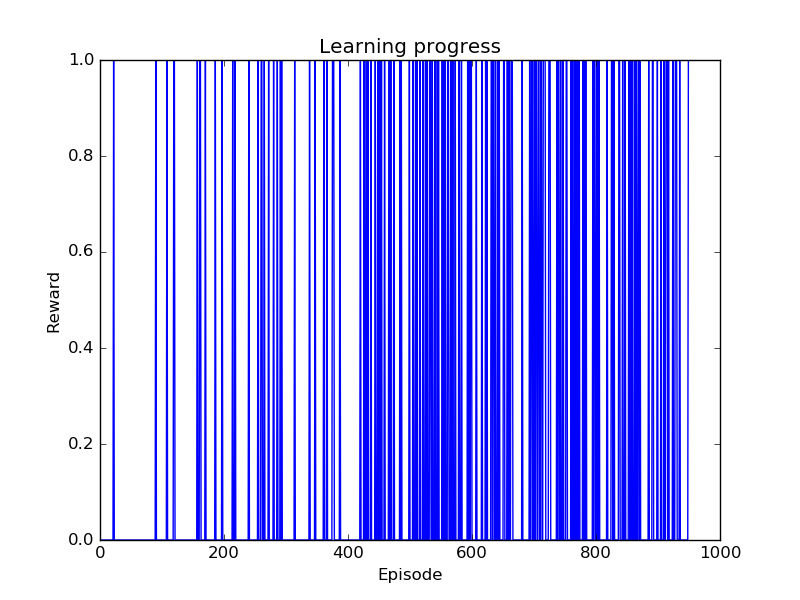
A simple problem with a discrete state and action space is solved with a tabular reinforcement learning algorithm. The plot shows the obtained return for each episode. Successful episodes terminate with the return 1, otherwise the return is 0. The learning process is stopped when the value function converged.
print(__doc__)
import matplotlib.pyplot as plt
from bolero.environment import OpenAiGym
from bolero.behavior_search import MonteCarloRL
from bolero.controller import Controller
env = OpenAiGym("FrozenLake-v0", render=False, seed=1)
env.init()
bs = MonteCarloRL(env.get_discrete_action_space(), random_state=1)
ctrl = Controller(environment=env, behavior_search=bs, n_episodes=10000,
finish_after_convergence=True)
rewards = ctrl.learn()
plt.figure()
ax = plt.subplot(111)
ax.set_title("Learning progress")
ax.plot(rewards)
ax.set_xlabel("Episode")
ax.set_ylabel("Reward")
plt.show()
Total running time of the script: ( 0 minutes 4.051 seconds)